
In January this year, the U.S. National Institutes of Health (NIH), the largest public funder of biomedical research in the world, implemented an updated data management and sharing (DMS) policy that will require all grant applications to be supported by, and comply with, a detailed DMS plan. The key requirements of the DMS plan include data/metadata volume and types along with their applied standards, tools, software, and code required for data access/analysis, and storage, access, distribution, and reuse protocols.
A pre-implementation NIH-sponsored multidisciplinary workshop to discuss this cultural shift in data management and sharing acknowledged that the policy was perceived more as a tax and an obligation than valued work within the research community. Researchers also feel overwhelmed by the lack of resources and expertise that will be required to comply with these new data management norms.
Biomedical research also has a unique set of data management challenges that have to be addressed in order to maximize the value of vast volumes of complex, heterogeneous, siloed, interdisciplinary, and highly regulated data. Plus, data management in life sciences is often seen as being a slow and costly process that is disruptive to conventional R&D workflows and with no direct RoI.
However, good data management can deliver cascading benefits for life sciences research – both for individual teams and the community. For research teams, effective data management standardizes data, code, and documentation. In turn, this enhances data quality, enables AI-driven workflows, and increases research efficiency. Across the broader community, it lays the foundation for open science, enhances reusability and reproducibility, and ensures research integrity. Most importantly, it is possible to create a strong and collaborative data management foundation by implementing established methodologies that do not disrupt current research processes or require reinventing the wheel.
Data management frameworks for life sciences
The key DMS requirements defined by the NIH encompass the remit of data management. Over the years, there has been a range of data management that have emerged from various disciplines that are broadly applicable to life sciences research.
However, the FAIR principles — Findability, Accessibility, Interoperability, and Reusability — published in 2016 were the first to codify the discipline of data management for scientific research. These principles focus on the unique challenges of scientific data from the perspective of the scientist rather than that of IT, and are applied to all components of the research process, including data, algorithms, tools, workflows, and pipelines.
It is widely acknowledged that implementing the FAIR principles can improve the productivity of biopharma and other life sciences R&D. The challenge, however, is that these high-level principles provide no specific technology, standard, or implementation recommendations. Instead, they merely provide the benchmark to evaluate the FAIRness of implementation choices. Currently, frameworks are in development to coordinate FAIRification among all stakeholders in order to maximize interoperability, promote the reuse of existing resources and accelerate the convergence of standards and technologies in FAIR implementations.
Although a move in the good direction, note that FAIR principles only cover a small part of data management. It is necessary to complement the FAIR principles with best practices form other, more holistic frameworks (data management or related), so here are a few worth looking at.
Data Management Body of Knowledge (DMBOK)
DMBOK from DAMA (Data Management Association) International, widely considered the gold standard of data management frameworks, was first published in 2009. It includes three distinct components – the DAMA wheel, the Environmental Factors hexagon, and the Knowledge Area Context Diagram.
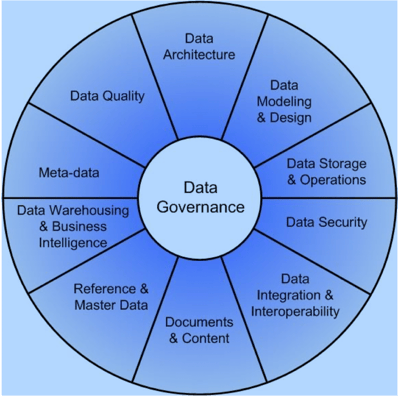
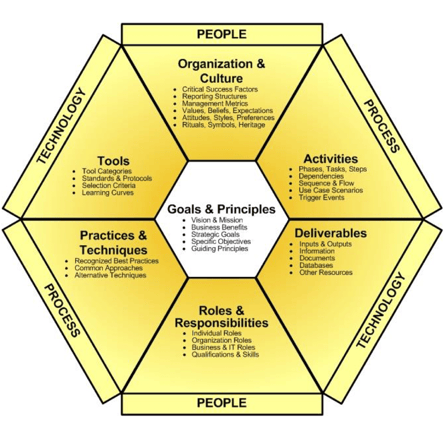
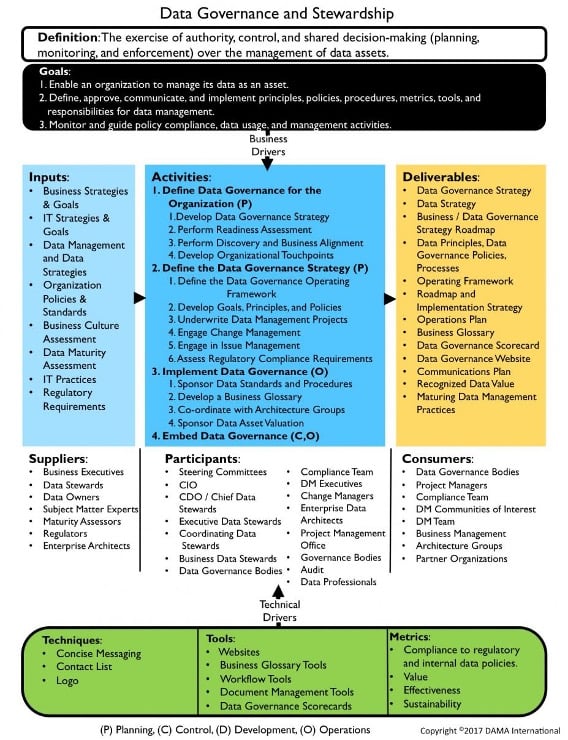
Image Source: DAMA International
The DAMA wheel defines 11 key knowledge areas that together constitute a mature data management strategy, the Environmental Factors Hexagon model provides the foundation for describing a knowledge area, with the Context Diagram framing its scope.
DMBOK2, released in 2017, includes some key changes. Data governance, for instance, is no longer just a grand unifying theory, but delivers contextual relevance by defining specific governance activities and environmental factors relevant to each knowledge area.
More broadly though, the DAMA-DMBOK Guide continues to serve as a comprehensive compilation of widely accepted principles and concepts that can help standardize activities, processes, and best practices, roles and responsibilities, deliverables and metrics, and maturity assessment.
Notwithstanding its widespread popularity, the DMBOK framework does have certain challenges. For instance, it has been pointed out that the framework’s emphasis on providing “...the context for work carried out by data management professionals…” overlooks all the non-data professionals working with data analytics today. Moreover, even though the model defines all the interrelated knowledge areas of data management, an integrated implementation of the entire framework from scratch would still require reinventing the wheel.
The Open Group Architecture Framework (TOGAF)
The TOGAF standard is a widely-used framework for enterprise architecture developed and maintained by members of The Open Group. The framework classifies enterprise architecture into four primary domains — business, data, application, and technology — spanned by other domains such as security, governance, etc. Data architecture is just one component in the framework’s approach to designing and implementing enterprise architecture, and TOGAF offers data models, architectures, techniques, best practices, and governance principles.
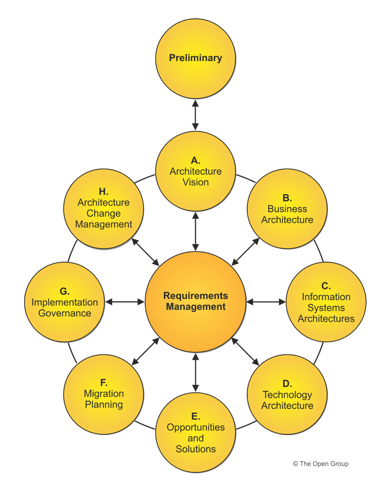
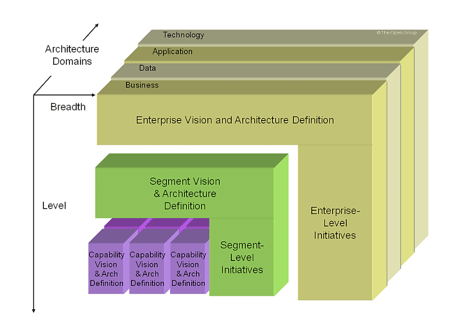
SOURCE: The Open Group
At the core of the TOGAF standard is the TOGAF Architecture Development Method (ADM) which describes the approach to developing and managing the lifecycle of an enterprise architecture. This includes TOGAF standard elements as well as other architectural assets that are available to meet enterprise requirements.
There are two more key parts to the TOGAF – the Enterprise Continuum and Architecture Repository. The Enterprise Continuum supports ADM execution by providing the framework and context to leverage relevant architecture assets, including architecture descriptions, models, and patterns sourced from enterprise repositories and other available industry models and standards. The Architecture Repository provides reference architectures, models, and patterns that have previously been used within the organization along with architecture development work-in-progress.
A key philosophy of the TOGAF framework is to provide a fully-featured core enterprise architecture metamodel that is broad enough to ensure out-of-the-box applicability across different contexts. At the same time, the open architecture standards enable users to apply a number of optional extension modules, for data, services, governance etc., to customize the metamodel to specific organizational needs.
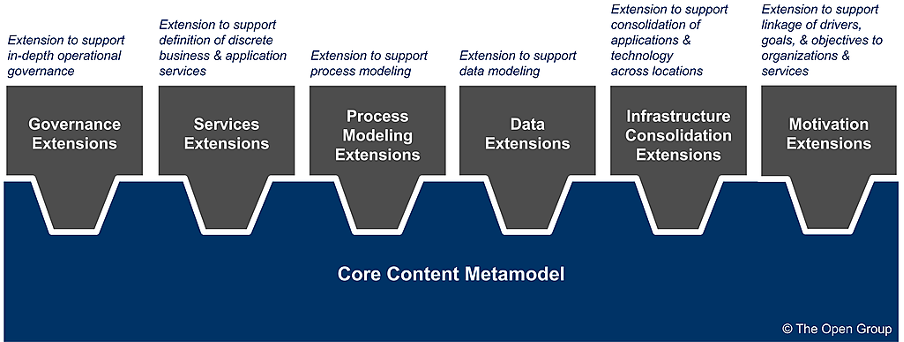
SOURCE: The Open Group
This emphasis on providing a universal scaffolding that is uniquely customizable started with
Version 9 of the standard. The 10th Edition, launched in 2022, is designed to embrace this dichotomy of universal concepts and granular configuration with a refreshed modular structure to streamline implementation across architecture styles and expanded guidance and “how-to” materials to simplify the adoption of best practices across a broad range of use cases.
IT Infrastructure Library (ITIL)
The ITIL framework was developed in the 1980s to address the lack of quality in IT services procured by the British Government as a methodology to achieve better quality at a lower cost.
The framework, currently administered and updated by Axelos, defines a 5-stage service lifecycle comprising service strategy, service design, service transition, service operations, and continuous service improvement.
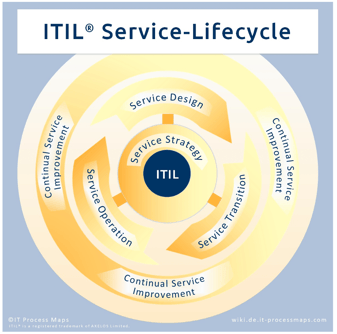
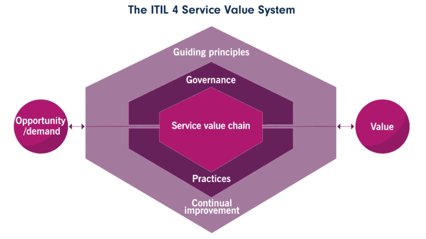
ITIL 4 continues to build on the core guidance of previous versions to deliver an adaptable framework that supports traditional service management activities, aligns to transformative cloud, automation, and AI technologies, and works seamlessly with DevOps, Lean, and Agile methodologies.
Although this is a framework for service management, it contains a number of interesting concepts, processes and metrics that relate to data management. One example is the use of configuration management databases (CMDBs).
CMDBs are a fundamental component of ITIL. These databases are used to store, manage and track information about individual configuration items (CIs), i.e., any asset or component involved in the delivery of IT services. The information recorded about each CI’s attributes, dependencies, and configuration changes allows IT teams to understand how components are connected across the infrastructure and focus on managing these connections to create more efficient processes.
Control Objectives for Information and Related Technology (COBIT)
COBIT is a comprehensive framework, created by ISACA (Information Systems Audit and Control Association) and first released in 1996. It defines the components and design factors required for implementing a management and governance system for enterprise IT.
Governance Framework Principles
SOURCE: ISACA
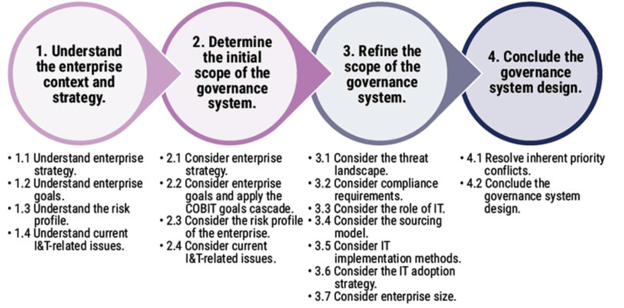
Governance System Design Workflow
SOURCE: ISACA
The latest release has shifted from ISO/IEC 33000 to the CMMI Performance Management Scheme and a new governance system design workflow has been adopted to streamline implementation.
COBIT, being a governance framework, contains interesting data governance related metrics, key performance indicators (KPIs) and processes on how an organization can follow up on quality and compliance, which is an essential part of good data management.
These are just a few examples of the different approaches to information and data management that are currently in use across industries. In fact, there are quite a lot more to choose from including the Gartner Enterprise Information Management Framework, Zachman Framework, Eckerson, PwC enterprise data governance framework, DCAM, SAS data governance framework, DGI data governance framework, and the list goes on.
Taking steps towards a better Data Management
The framework around FAIR principles certainly provided a good starting place for getting the basics of your data management right. In this blog we’ve shown that this alone is not enough, and we demonstrated the plethora of frameworks out there that are widely used and proven. They are priceless in avoiding reinventing the wheel and can accelerate your road to improving your data management. At BioStrand, we have taken useful elements out of all these standards and frameworks to arrive at a mature data management strategy that guides the implementation of all our services.
In the following blog in this series, we'll look at how a modern information architecture could set the foundation for enterprise-centric AI deployments.
Stay tuned.
Read Part 2 of our Data Management Series: Creating a unified data + information architecture for scalable AI
Read Part 3 of our Data Management Series: AI-powered data integration and management with data fabric


