
So far in our blog series on data management, we’ve looked at some of the most commonly used data and information frameworks, and the imperative to create a unified data + information architecture in order to achieve AI deployment at scale.
In this third blog, we explore the evolution of data architectures, with a closer view of data fabric, one of the leading modern data architecture paradigms.
A data architecture is the blueprint that, in simple terms, aligns an organization’s data assets with its strategic objectives. The approaches to data architecture have evolved significantly over the years to reflect changing data characteristics (volume, variety, diversity, etc.), emergent technologies (cloud, AI, ML, etc.), and the dynamics of the modern digital corporation.
The Evolution Of Data Architectures
SOURCE: Evolving Data Architectures - Eckerson Group
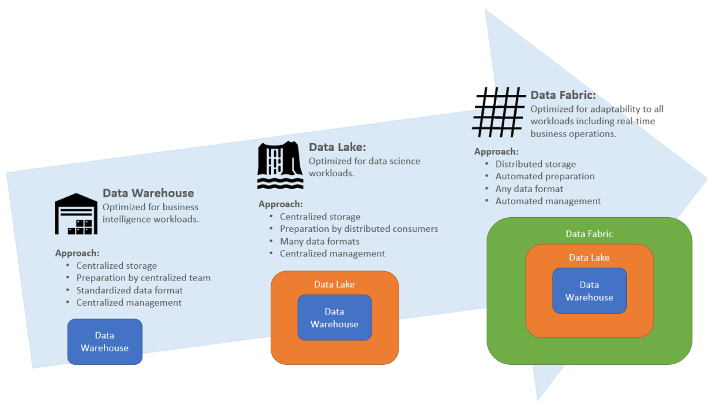
There are, broadly, three generations of data architecture—data warehouses, data lakes, and data fabric or data mesh. Data warehouses were one of the first approaches that focused on creating a unified view of enterprise data. A data warehouse was a centralized repository for structured data and required a specialized data team to prepare data for consumption by analysts, predominantly.
Data lakes became prominent in the 2010s as a solution to dealing with unstructured big data. Data lakes process structured, semi-structured, and unstructured data at scale and store them in their native format in a centralized repository. A data lake architecture uses the Extract, Load, Transform (ELT), rather than the Extract, Transform, Load (ETL), process whereby data is loaded with very little or no transformation. This enables more flexibility in the transformation of data to specific needs. Though data lakes are the current industry standard for data architecture, they still present some challenges in terms of data reliability, query performance, and governance.
The increasing distribution of data across multiple data warehouses and data lakes, and cloud and on-premise environments has amplified the complexity involved in the movement, transformation, integration, and delivery of distributed data. As a result data architectures are now evolving into the Active Metadata Era involving two complementary approaches; the data fabric and the data mesh. Although data mesh provides a valid alternative or complement to a data fabric setup, in this blog we focus solely on the data fabric solution. This is by no means an argument for data fabric over data mesh, and future blogs may explore the data mesh route.
A data fabric design enables organizations to augment the ROI of their existing data investments across different databases, architectures, and integration platforms. It represents a centralized approach to managing and accessing distributed data across multiple formats, locations, and systems. A data fabric is not designed to collect and store information but rather to connect data across disparate repositories to provide a unified view of all business-relevant data. Metadata, provided by data repositories, is one of the key value drivers of a data fabric, which then utilize semantic knowledge graphs, metadata management, and machine learning to contextually unify existing data and for the intelligent integration of new data. A metadata-driven data fabric/mesh architecture will enable organizations to optimize data integration and delivery while ensuring data quality reusability, and governance.
The 4 Key Pillars Of A Data Fabric Architecture
According to Gartner, there are four key pillars of a data fabric architecture:
- Continuous metadata collection & analysis: A data fabric is essentially a metadata-driven architecture to integrate and deliver enriched data to users. A key requirement, therefore, is the continuous collection and analysis of all types of metadata such as technical, business, operational, and social. This architecture relies on discoverable and inferenced metadata assets to orchestrate the integration and deployment of data across all environments.
- Convert passive metadata to active metadata: A data fabric architecture collects all types of metadata and uses graph analytics to depict both discovered and inferred data based on their unique relationships. Applying learning algorithms to key metadata metrics can help identify patterns that enable the automated enrichment of data sources and advanced predictions for more efficient data management and integration.
- Create and curate knowledge graphs: A knowledge graph intelligently curates related structured, semi-structured, and unstructured data and metadata from different silos with unprecedented granularity and flexibility in data integration. The semantic layer provides users with a more intuitive method for querying and consuming data. Semantic knowledge graph technologies can also help merge the top-down and bottom-up philosophies of the data fabric and data mesh into a unified architecture that is domain-focused as well as enterprise-centric.
- Automated data integration: A data fabric must enable the dynamic AI-driven integration of highly distributed data and metadata with a high degree of automation, speed, and intelligence while ensuring data quality and security. It must be compatible with multiple data pipelines, environments, and integration styles. And finally, intelligent data integration must be capable of learning and improving over time and help future-proof enterprise data infrastructure.
The Data Fabric-AI Symbiosis
At-scale AI deployments require the integration of large volumes of high-quality data, and well-governed data from disparate and distributed data sources. The lack of a purpose-built data infrastructure is often the main bottleneck that results in organizations spending as much time and effort on sourcing, ingesting, and transforming data as they do on AI model development.
Organizations can leverage the symbiotic relationship between data fabrics and AI. On the one hand, a data fabric combines valuable metadata with AI/ML capabilities and knowledge graphs to create a flexible, real-time, and automated data integration and management platform. The key benefits of this approach include augmented data integration across hybrid environments, automated data engineering, governance, and security, and self-service data consumption for all users.
A data fabric, on the other hand, also aggregates high-quality, accurate data from disparate sources and delivers comprehensive and trusted data sets for self-service consumption. A fabric architecture also allows organizations to implement the right rules and policies for the access and use of data and establish guardrails during model building, deployment, management, and monitoring. And finally, a data fabric enables trustworthy AI by facilitating the automatic monitoring and control of AI models based on predefined governance rules.
The data fabric, together with the data mesh, represents an evolutionary step up from more conventional database-centric models like data warehouses or data lakes. However, it is not intended to replace conventional systems but instead enhance existing data infrastructure investments by augmenting the utility of data assets such as warehouses, lakes, catalogs, etc.
Read Part 1 of our Data Management Series: From FAIR principles to holistic data management in life sciences
Read Part 2 of our Data Management Series: Creating a unified data + information architecture for scalable AI


